《亚马逊僵尸链接挖掘器》(亚马逊僵尸listing)是一款用于挖掘亚马逊(AMAZON)僵尸链接(无主ASIN)的工具,可以从搜索结果列表和类目页面自动翻页挖掘,这个模式的和好处是可以找到和自己产品相关或者同类目的僵尸链接,软件还可以分析僵尸链接的品牌、销售排名、评论星级、评论数量和评论中是否带图片,以及从Tmdn.org查询品牌是否被注册。
本篇介绍如何使用《亚马逊僵尸链接挖掘器》软件:
一、在搜索页面中挖掘
1、搜索网址列表
这里提供了两个输入方式,可以做一个TXT,一行一条用于挖掘的搜索网址,或者在文本框里直接填入一行一条搜索网址;
获取搜索网址的方法:
打开亚马逊首页,这里用亚马逊主站作为例子介绍,打开www.amazon.com,主页搜索框输入你要挖掘的僵尸链接(无主ASIN)的相关关键词,然后点击搜索,浏览器地址栏中的网址就是你要获取的搜索网址,复制到软件;
得到的搜索网址例如:https://www.amazon.com/s?k=screw&ref=nb_sb_noss
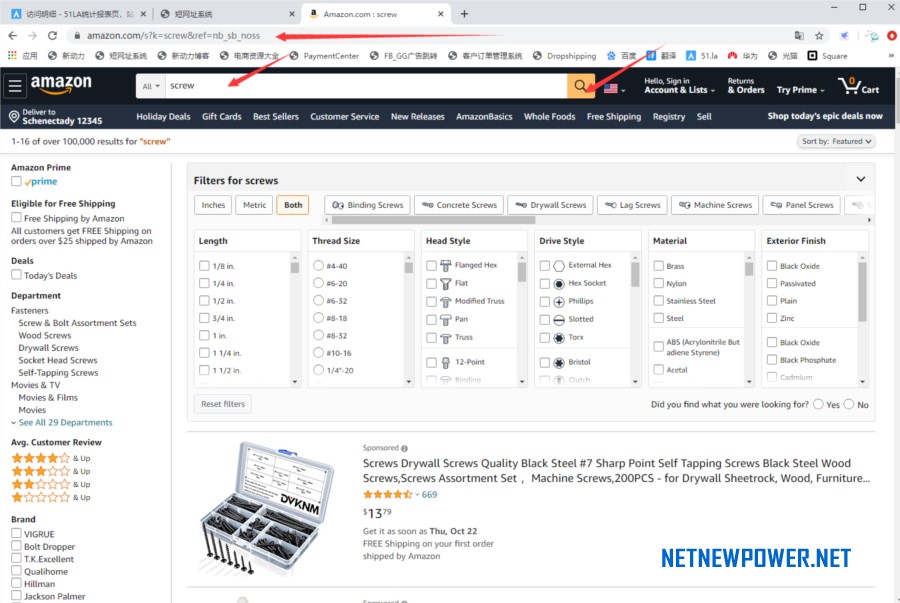
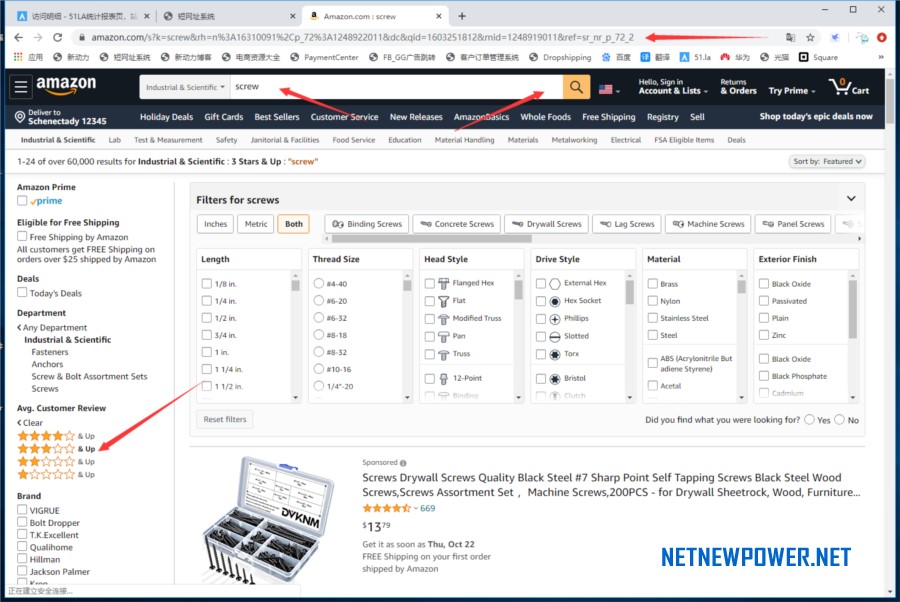
再看看左侧有一个评论星级选项,如果预先点击了星级选项,你得到的搜索网址挖掘出来的僵尸链接(无主ASIN)就是有指定要求星级的,点击之后操作和前面一样;
得到的搜索网址例如:https://www.amazon.com/s?k=screw&i=industrial&rh=n%3A16310091%2Cp_72%3A1248923011&dc&qid=1603252181&rnid=1248919011&ref=sr_nr_p_72_3
2、只抓取当前列表(采用软件默认设置即可):
不选中的话软件会自动一级一级子分类下去挖掘,反之就是只抓取当前分类;
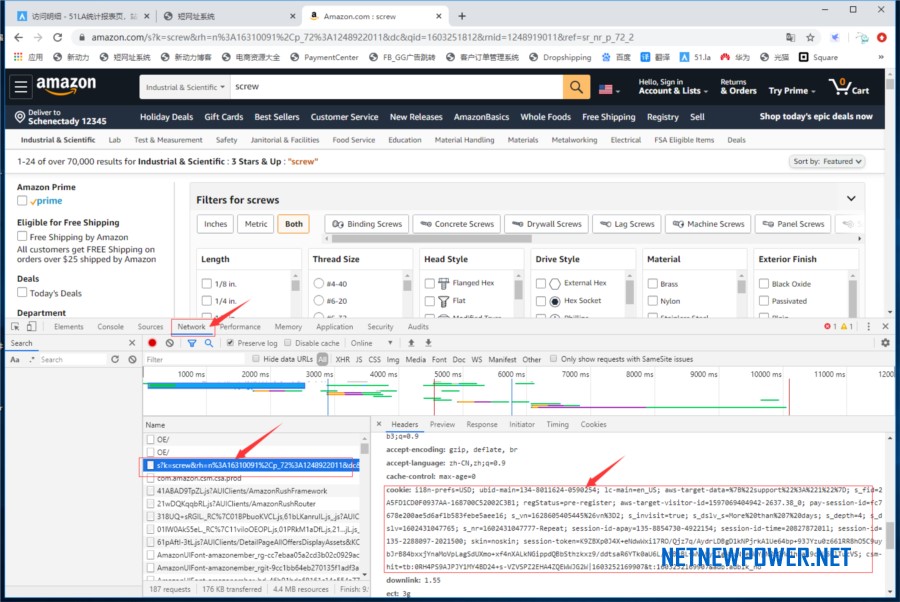
3、Cookie
由于亚马逊是根据访问人的国家地域来显示产品列表和产品内容的,我们需要改变亚马逊的邮编设置来定位指定国家地域以获取正确的产品列表,关于这一步COOKIE获取操作可以看这篇文章:使用谷歌Chrome浏览器获取亚马逊Cookie的方法
4、代理IP选项(采用软件默认设置即可):
如果采集数量大亚马逊会封IP,这个时候就需要购买一些私人代理来导入软件,以偏可以持久采集挖掘;
但是一般来说单线程运行模式下不用代理IP也可以正常运行,这一步可以暂不考虑;
5、超时时间(采用软件默认设置即可):
指的是采集一页的最大时间,超过就自动重新采集,单位是毫秒;
6、间隔时间(采用软件默认设置即可):
指的是采集一页之后等待多少时间再去采集下一页,单位是毫秒;
7、线程数:
建议设置线程数1,这样不用代理IP也可以持续跑,大于1个话频繁出现限制IP了就需要考虑购买代理IP运行软件了;
8、定位串:
这个参数可以自定义,用于标记数据批次,给定了一个特定标记的一批数据,在后续模块中可以根据这个定位串筛选数据,那么可以指定对这批数据进行导出数据、亚马逊僵尸链接检测、商标查询,而不必每次都所有数据一起操作。
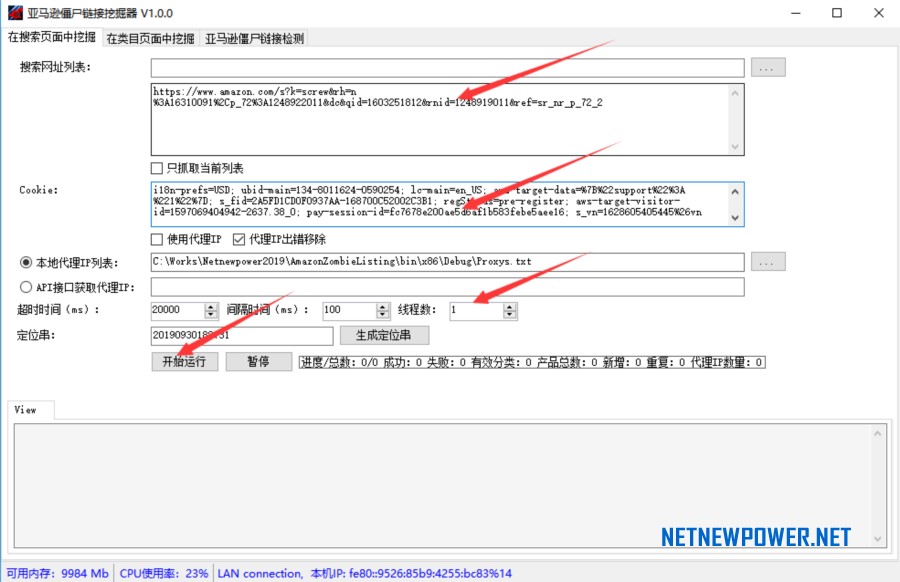
9、软件运行中需要关注的参数:
新增数量表示抓到了几个新的僵尸链接(无主ASIN),当软件运行到进度=总数,并且输出界面没有新增内容了,就代表本次运行完成了,可以点关闭运行了。
挖掘到的僵尸链接(无主ASIN)可以在第三个模块的筛选/管理中看到,还可以进行筛选、删除、导出表格、亚马逊僵尸链接检测和品牌注册情况查询操作。
二、在类目页面中挖掘
这个模块和第一个模块类似,只是使用的搜索网址直接是类目网址,例如:https://www.amazon.com/gp/browse.html?node=3741481
三、亚马逊僵尸链接检测
1、筛选管理、导入和导出
第一、第二个模块挖掘到的僵尸链接(无主ASIN)数据都列表显示在这里,可以进行筛选、删除、导入和导出操作;
2、亚马逊僵尸链接检测
第一、第二个模块挖掘到的僵尸链接(无主ASIN)数据,可以使用此模块进一步进行检测获取到每个ASIN的品牌词、排名、评论数量、评论星级和评论中是否带图等数据;
3、注册商标查询
第一、第二个模块挖掘到的僵尸链接(无主ASIN)数据,在运行亚马逊僵尸链接检测,获取到品牌词之后,可以使用此模块查询品牌的注册情况;
关于注册商标查询中的获取COOKIE教程,可以查看这篇教程:商标查询网站TMDN.ORG的COOKIE获取方法
发表回复